目录
算法介绍
基本原理
1. 体渲染
2. 多层感知机(MLP)
3. 位置编码
4. 两阶段层次化体采样
实验展示
代码解析
算法介绍
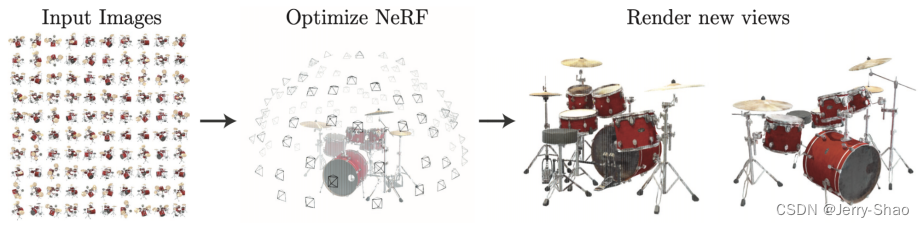
NeRF(Neural Radiance Fields)是一种用于从2D图像中重建3D场景的神经网络模型。它通过训练一个深度神经网络来预测任意3D空间点的颜色和密度,从而实现对场景的精确重建。为了训练网络,针对一个静态场景,需要提供包含大量相机参数已知的图片的训练集,以及图片对应的相机所处3D坐标,相机朝向(2D,但实际使用3D单位向量表示方向)。使用多视角的数据进行训练,空间中目标位置具有更高的密度和更准确的颜色,促使神经网络预测一个连续性更好的场景模型。
NeRF的关键思想是将场景表示为辐射场,即每个空间点的颜色和密度可以由一个神经网络来表示。通过在训练与真实观察值之间的差异,学习到场景的几何形状和光照信息。
基本原理
1. 体渲染
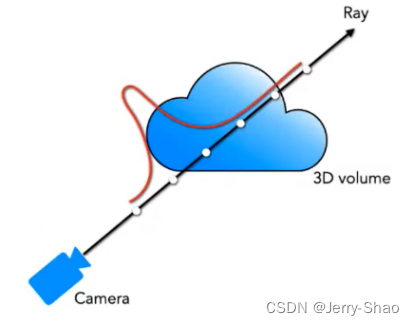
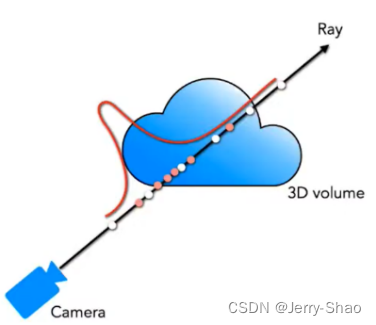
体渲染是指根据三维空间中的密度和颜色信息,通过光线追踪等技术将体积数据转换成图像的过程。在 NeRF 中,体渲染用于生成逼真的图像,通过对场景中的三维结构和光照进行建模,从而实现高质量的渲染效果。
下图是体渲染建模的示意图。光沿直线方向穿过一堆粒子 (粉色部分),如果能计算出每根光线从最开始发射,到最终打到成像平面上的辐射强度,我们就可以渲染出投影图像。为了简化计算,我们就假设光子只跟它附近的粒子发生作用,这个范围就是图中圆柱体大小的区间。

2. 多层感知机(MLP)
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络,除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
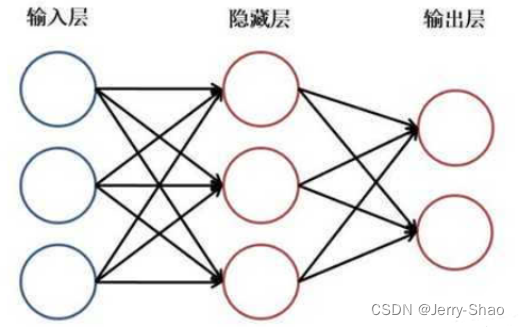
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,用于接收外部数据。中间是隐藏层,用于提取和学习数据中的特征,并西将信号加权求和输出给下一次。最后是输出层,用于输出模型预测结果。
NeRF函数是将一个连续的场景表示为一个输入为5D向量的函数,下图的实现中,x首先输入到MLP网络中,并输出σ和一个256维的中间特征,中间特征和d再一起输入到额外的全连接层(128维)中预测颜色。

3. 位置编码
在神经网络中,特别是用于处理三维空间数据的模型中,位置编码是一种用来表示对象或特征在空间中位置信息的技术。如NeRF通过使用位置编码来捕获场景中不同点的位置信息以实现多个视角重建三维场景。
比较下图中的四个效果,可以观察到第四个效果没有加位置编码,使得该图的效果就不清晰。

4. 两阶段层次化体采样
NeRF的渲染策略是对相机发出的每条射线进行N个采样,将颜色加权求和,得到该射线颜色。为了更好的采样,提出两阶段层次化体素采样 的方式,即先按照均匀随机采样进行一次粗采样,将粗采样的输出的结果转化为分布,再根据分布进行一次精采样,最后NeRF训练的损失也是粗采样和精采样结果相加的结果,这样就实现了一个自动化Coarse-To-Fine的训练过程。如下图所示。
实验展示
下列是运用nerf在不同场景下渲染出的不同角度的视频截图:
效果一:




效果二:




效果三:




代码解析
run_nerf.py
该代码使用了一个结构化的方法来实现基于NeRF的渲染系统,提供必要的工具,有效地训练和渲染3D场景。代码中主要实现了使用神经辐射场(NeRF)的体积渲染功能。它包括用于设置NeRF模型、渲染场景、处理数据和优化训练过程的实用程序。关键的功能,例如 batchify, run_network, render, raw2outputs, 和 render_rays定义用于处理任务,如将函数应用于批处理、运行神经网络、渲染射线以及将模型预测转换为有意义的输出(如RGB颜色和深度图)。该代码还支持重要性采样、检查点加载和精细的NeRF模型实例化,以增强渲染质量。
def batchify(fn, chunk): # 构建一个将原始函数fn应用于较小批次的函数。
"""Constructs a version of 'fn' that applies to smaller batches.
"""
if chunk is None: # 如果chunk为None,
return fn # 则直接返回原始函数fn
def ret(inputs): # 如果chunk不为None,则定义一个新的函数ret,该函数接受输入inputs
return torch.cat([fn(inputs[i:i + chunk]) for i in range(0, inputs.shape[0], chunk)],
0) # 将输入数据按照chunk大小分成小批次,然后逐个批次应用原始函数fn,最后将结果连接起来并返回
return ret # 返回一个函数对象ret
def run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn,
netchunk=1024 * 64): # 定义了一个函数run_network,用于准备输入数据并将其应用于网络函数fn
"""Prepares inputs and applies network 'fn'.
"""
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]]) # 将输入数据inputs进行扁平化处理,以便传入嵌入函数。
embedded = embed_fn(inputs_flat) # 使用embed_fn对扁平化后的输入数据进行嵌入操作,得到嵌入向量embedded
if viewdirs is not None: # 如果viewdirs不为None
input_dirs = viewdirs[:, None].expand(inputs.shape) # 将视角方向viewdirs扩展为与输入数据inputs相同的形状
input_dirs_flat = torch.reshape(input_dirs,
[-1, input_dirs.shape[-1]]) # 将经过扩展后的视角方向张量input_dirs重新整形为一个二维张量input_dirs_flat
embedded_dirs = embeddirs_fn(input_dirs_flat) # 调用函数embeddirs_fn,将经过重新整形的视角方向数据input_dirs_flat作为输入,进行视角方向的嵌入操作
embedded = torch.cat([embedded, embedded_dirs], -1) # 将视角方向的嵌入表示embedded_dirs与输入数据的嵌入表示embedded进行了拼接
outputs_flat = batchify(fn, netchunk)(embedded) # 将拼接后的嵌入表示embedded分批次应用给定的网络函数fn,使用batchify函数处理
outputs = torch.reshape(outputs_flat,
list(inputs.shape[:-1]) + [outputs_flat.shape[-1]]) # 将输出结果重新整形为与输入数据相同形状的张量outputs
return outputs # 返回处理后的输出结果
def batchify_rays(rays_flat, chunk=1024 * 32, **kwargs): # 定义了一个函数batchify_rays,用于在较小的小批次中渲染光线,以避免内存溢出问题
"""Render rays in smaller minibatches to avoid OOM.
"""
all_ret = {} # 创建一个空字典,用于存储所有小批次渲染的结果
for i in range(0, rays_flat.shape[0], chunk): # 通过循环,将光线数据rays_flat按照指定的chunk大小分成小批次进行处理
ret = render_rays(rays_flat[i:i + chunk],
**kwargs) # 当前批次的光线数据进行渲染操作,调用render_rays函数,并将渲染结果存储在ret中。rays_flat[i:i+chunk]表示当前批次的光线数据。
for k in ret: # 遍历渲染结果ret中的键(key)
if k not in all_ret: # 如果当前键k不在all_ret字典中
all_ret[k] = [] # 将其初始化为空列表
all_ret[k].append(ret[k]) # 将当前批次的渲染结果ret[k]添加到all_ret[k]列表中,实现将不同批次的渲染结果按键分别存储在all_ret字典中
all_ret = {k: torch.cat(all_ret[k], 0) for k in all_ret} # 通过字典推导式,遍历all_ret字典中的每个键值对,对值(列表)进行拼接操作
return all_ret # 将合并后的结果字典返回
def render(H, W, K, chunk=1024 * 32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs): # 定义了一个render函数,用于渲染场景并返回渲染结果
if c2w is not None: # 如果提供了相机到世界坐标系的变换矩阵c2w
# special case to render full image
rays_o, rays_d = get_rays(H, W, K,
c2w) # 调用get_rays函数,根据图像的高度H、宽度W和相机内参K以及相机到世界坐标系的变换矩阵c2w,获取光线的起点rays_o和方向rays_d
else: # 如果未提供相机到世界坐标系的变换矩阵c2w
# use provided ray batch
rays_o, rays_d = rays # 使用提供的光线数据rays作为光线的起点和方向,即直接使用提供的光线数据作为渲染的输入
if use_viewdirs: # 如果需要使用视角方向信息
# provide ray directions as input
viewdirs = rays_d # 将光线方向rays_d作为视角方向viewdirs
if c2w_staticcam is not None: # 如果存在静态相机到世界坐标系的变换矩阵c2w_staticcam
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K,
c2w_staticcam) # 根据图像的高度H、宽度W和相机内参K以及静态相机到世界坐标系的变换矩阵c2w_staticcam,获取新的光线的起点和方向
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True) # 对视角方向进行归一化处理,即将视角方向向量除以其模长,使其变为单位向量
viewdirs = torch.reshape(viewdirs, [-1, 3]).float() # 将归一化后的视角方向重新整形为二维张量,以便后续处理
sh = rays_d.shape # [..., 3] # 获取光线方向rays_d的形状,用变量sh保存,形状为[..., 3],表示每个光线方向由三个分量组成
if ndc: # 如果需要使用归一化设备坐标系(NDC),则执行以下操作
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d) # 调用ndc_rays函数,对光线的起点和方向进行NDC转换,以适应前向场景的渲染需求
# Create ray batch
rays_o = torch.reshape(rays_o, [-1, 3]).float() # 将光线起点rays_o重新整形为二维张量,并转换为浮点型数据类型
rays_d = torch.reshape(rays_d, [-1, 3]).float() # 将光线方向rays_d重新整形为二维张量,并转换为浮点型数据类型
near, far = near * torch.ones_like(rays_d[..., :1]), far * torch.ones_like(
rays_d[..., :1]) # 根据近平面和远平面的距离,创建与光线方向相同形状的张量
rays = torch.cat([rays_o, rays_d, near, far], -1) # 将光线起点、方向、近平面和远平面拼接成一个光线批次数据rays,以便进行批次渲染
if use_viewdirs: # 如果使用视角方向信息
rays = torch.cat([rays, viewdirs], -1) # 将视角方向信息拼接到光线批次数据中,以考虑视角方向对渲染的影响
# Render and reshape
all_ret = batchify_rays(rays, chunk, **kwargs) # 调用batchify_rays函数,对光线批次数据进行分批次渲染,返回渲染结果的字典all_ret
for k in all_ret: # 遍历渲染结果字典all_ret中的每个键(key)
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:]) # 根据光线方向的形状sh和当前渲染结果的形状,构建新的形状k_sh,保持与原始光线方向形状相同
all_ret[k] = torch.reshape(all_ret[k], k_sh) # 将当前渲染结果按照新的形状k_sh进行重新整形,以确保与光线方向形状相匹配
k_extract = ['rgb_map', 'disp_map', 'acc_map'] # 指定需要提取的渲染结果的键列表
ret_list = [all_ret[k] for k in k_extract] # 根据指定的键列表k_extract,提取对应的渲染结果,存储在ret_list中
ret_dict = {k: all_ret[k] for k in all_ret if
k not in k_extract} # 根据渲染结果字典all_ret中的键,将不在提取列表k_extract中的渲染结果存储在ret_dict中
return ret_list + [ret_dict] # 将提取的渲染结果列表和剩余的渲染结果字典作为列表的形式返回,其中列表包含提取的渲染结果和剩余的渲染结果字典
def render_path(render_poses, hwf, K, chunk, render_kwargs, gt_imgs=None, savedir=None, render_factor=0):
# 定义了一个render_path函数,用于根据渲染姿态、相机参数等信息渲染场景,并返回渲染结果
H, W, focal = hwf # 从hwf中解包出图像的高度、宽度和焦距
if render_factor != 0: # 如果render_factor不等于0,则执行下面的操作
# Render downsampled for speed
H = H // render_factor # 将图像的高度按照render_factor进行缩放
W = W // render_factor # 将图像的宽度按照render_factor进行缩放
focal = focal / render_factor # 将焦距按照render_factor进行缩放
rgbs = [] # 初始化一个空列表rgbs,用于存储渲染的RGB图像
disps = [] # 初始化一个空列表disps,用于存储渲染的深度图像
t = time.time() # 记录当前时间,用于计算渲染时间
for i, c2w in enumerate(tqdm(render_poses)): # 历渲染姿态列表render_poses,使用tqdm显示进度条,并对每个姿态进行渲染
print(i, time.time() - t) # 打印当前渲染的索引和上一个渲染的时间间隔
t = time.time() # 更新时间记录
rgb, disp, acc, _ = render(H, W, K, chunk=chunk, c2w=c2w[:3, :4],
**render_kwargs) # 调用render函数进行图像渲染,获取RGB图像、深度图像、准确度和其他信息
rgbs.append(rgb.cpu().numpy()) # 将渲染得到的RGB图像转换为NumPy数组并添加到rgbs列表中
disps.append(disp.cpu().numpy()) # 将渲染得到的深度图像转换为NumPy数组并添加到disps列表中
if i == 0: # 如果是第一次渲染,则执行以下操作
print(rgb.shape, disp.shape) # 打印RGB图像和深度图像的形状
"""
if gt_imgs is not None and render_factor==0:
p = -10. * np.log10(np.mean(np.square(rgb.cpu().numpy() - gt_imgs[i])))
print(p)
"""
if savedir is not None: # 如果指定了保存目录,则执行以下操作
rgb8 = to8b(rgbs[-1]) # 将最新的RGB图像转换为8位表示
filename = os.path.join(savedir, '{:03d}.png'.format(i)) # 构建保存文件的路径和文件名
imageio.imwrite(filename, rgb8) # 将RGB图像保存为PNG格式文件
rgbs = np.stack(rgbs, 0) # 将所有RGB图像堆叠成一个数组
disps = np.stack(disps, 0) # 将所有深度图像堆叠成一个数组
return rgbs, disps # 返回所有渲染的RGB图像和深度图像数组
def create_nerf(args): # 定义了一个create_nerf函数,用于实例化 NeRF 的 MLP 模型,并设置训练所需的参数和优化器
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed) # 调用get_embedder函数获取嵌入器函数和输入通道数
input_ch_views = 0 # 初始化视角方向的输入通道数为0
embeddirs_fn = None # 初始化视角方向的嵌入器函数为None
if args.use_viewdirs: # 如果使用视角方向信息,则执行以下操作
embeddirs_fn, input_ch_views = get_embedder(args.multires_views,
args.i_embed) # 根据视角方向的多分辨率参数和输入嵌入维度获取视角方向的嵌入器函数和输入通道数
output_ch = 5 if args.N_importance > 0 else 4 # 根据重要性采样数量确定输出通道数
skips = [4] # 设置跳跃连接列表
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device) # 创建主要的 NeRF 模型,并将其移动到指定设备
grad_vars = list(model.parameters()) # 获取模型的参数列表
model_fine = None # 初始化细化模型为None
if args.N_importance > 0: # 如果需要重要性采样,则执行以下操作
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(
device) # 创建细化的 NeRF 模型,并将其移动到指定设备
grad_vars += list(model_fine.parameters()) # 将细化模型的参数添加到参数列表中
network_query_fn = lambda inputs, viewdirs, network_fn: run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk) # 定义网络查询函数,用于运行网络
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999)) # 创建 Adam 优化器
start = 0 # 初始化起始步数为0
basedir = args.basedir # 获取基础目录
expname = args.expname # 获取实验名称
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path != 'None': # 如果提供了微调路径,则执行以下操作
ckpts = [args.ft_path] # 将微调路径添加到检查点列表中
else: # 否则,执行以下操作
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if
'tar' in f] # 根据基础目录和实验名称获取所有检查点文件路径
print('Found ckpts', ckpts) # 打印找到的检查点文件路径
if len(ckpts) > 0 and not args.no_reload: # 如果存在检查点文件且不禁止重新加载,则执行以下操作
ckpt_path = ckpts[-1] # 获取最新的检查点文件路径
print('Reloading from', ckpt_path) # 打印重新加载的检查点文件路径
ckpt = torch.load(ckpt_path) # 加载检查点文件
start = ckpt['global_step'] # 获取全局步数
optimizer.load_state_dict(ckpt['optimizer_state_dict']) # 加载优化器状态字典
# Load model
model.load_state_dict(ckpt['network_fn_state_dict']) # 如果存在细化模型,则执行以下操作
if model_fine is not None: # 如果存在细化模型,则执行以下操作
model_fine.load_state_dict(ckpt['network_fine_state_dict']) # 加载细化模型的状态字典
##########################
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc: # # 如果数据集类型不是LLFF或禁用NDC,则执行以下操作
print('Not ndc!')
render_kwargs_train['ndc'] = False # 设置不使用NDC
render_kwargs_train['lindisp'] = args.lindisp # 设置线性深度
render_kwargs_test = {k: render_kwargs_train[k] for k in render_kwargs_train} # 设置测试渲染参数
render_kwargs_test['perturb'] = False # 表示在测试阶段不进行扰动操作,即不对输入进行随机扰动,保持输入不变
render_kwargs_test['raw_noise_std'] = 0. # 表示在测试阶段不添加原始噪声
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer # 返回训练和测试的渲染参数、起始步数、梯度变量和优化器
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False): # 将原始数据转换为输出结果。
raw2alpha = lambda raw, dists, act_fn=F.relu: 1. - torch.exp(
-act_fn(raw) * dists) # 定义一个名为raw2alpha的lambda函数,接受三个参数:raw, dists和act_fn(默认为F.relu)
# 函数的主要功能是计算1减去以act_fn(raw)乘以dists为指数的负指数值
dists = z_vals[..., 1:] - z_vals[..., :-1] # 计算z_vals数组中相邻元素之间的差值,并将结果存储在dists变量中
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[..., :1].shape)],
-1) # [N_rays, N_samples] 将dists张量与一个值为1e10的张量进行拼接,新张量的维度与dists的前n-1个维度相同,最后一个维度为1
dists = dists * torch.norm(rays_d[..., None, :], dim=-1) # 计算射线方向的范数,并将其与距离相乘
rgb = torch.sigmoid(raw[..., :3]) # [N_rays, N_samples, 3] # 使用torch.sigmoid函数对raw张量的最后一维的前三个通道进行激活操作,并将结果赋值给rgb变量
noise = 0. # 初始化噪声值为0
if raw_noise_std > 0.: # 判断原始噪声标准差是否大于0
noise = torch.randn(raw[..., 3].shape) * raw_noise_std # 如果大于0,则生成一个与raw[...,3]形状相同的随机噪声矩阵,并乘以原始噪声标准差
# Overwrite randomly sampled data if pytest
if pytest: # 如果pytest为真,执行以下代码块
np.random.seed(0) # 设置随机数种子,确保每次运行结果一致
noise = np.random.rand(*list(raw[..., 3].shape)) * raw_noise_std # 生成与raw[...,3]形状相同的随机噪声,并乘以raw_noise_std
noise = torch.Tensor(noise) # 将生成的噪声转换为PyTorch张量
alpha = raw2alpha(raw[..., 3] + noise,
dists) # [N_rays, N_samples] # 定义一个变量alpha,将raw数组的第四维(索引为3)与noise相加,然后将结果传递给raw2alpha函数,同时传入dists参数
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1. - alpha + 1e-10], -1), -1)[:,
:-1] # 创建一个全1矩阵,形状与alpha相同,列数为1 #使用alpha值计算权重
rgb_map = torch.sum(weights[..., None] * rgb, -2) # [N_rays, 3] # 使用torch库计算权重和rgb的加权和,将结果存储在rgb_map中
depth_map = torch.sum(weights * z_vals, -1) # 计算权重和z_vals的逐元素乘积,然后沿着最后一个维度求和,得到深度图
disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights,
-1)) # 创建一个与depth_map形状相同的全1张量,并乘以1e-10,用于避免除以0的情况 计算depth_map与weights的逐元素相除,然后沿着最后一个维度求和 # 使用torch.max函数找到ones_like_depth_map和depth_map_divided_by_sum_weights中的最大值 计算1除以最大值,得到disp_map
acc_map = torch.sum(weights, -1) # 使用torch库的sum函数,对weights张量沿着最后一个维度(-1表示最后一个维度)求和,得到的结果赋值给acc_map变量
if white_bkgd: # 判断是否需要白色背景
rgb_map = rgb_map + (1. - acc_map[..., None]) # 如果需要白色背景,将rgb_map与(1.-acc_map[...,None])相加
return rgb_map, disp_map, acc_map, weights, depth_map # 返回rgb_map, disp_map, acc_map, weights, depth_map
# 渲染射线的函数
def render_rays(ray_batch, # 包含射线信息的字典
network_fn, # 用于生成射线的神经网络函数
network_query_fn, # 用于查询射线结果的神经网络函数
N_samples, # 采样点的数量
retraw=False, # 是否返回原始数据,默认为False
lindisp=False, # 是否使用线性视差,默认为False
perturb=0., # 扰动值,默认为0.0
N_importance=0, # 重要采样点的数量,默认为0
network_fine=None, # 精细网络函数,默认为None
white_bkgd=False, # 是否使用白色背景,默认为False
raw_noise_std=0., # 原始噪声标准差,默认为0
verbose=False, # 是否输出详细信息,默认为False
pytest=False): # 是否进行测试,默认为False
N_rays = ray_batch.shape[0] # 获取光线的数量
rays_o, rays_d = ray_batch[:, 0:3], ray_batch[:, 3:6] # [N_rays, 3] each # 将光线批次分为起点和方向,每个都是一个形状为 [N_rays, 3] 的张量
viewdirs = ray_batch[:, -3:] if ray_batch.shape[-1] > 8 else None # 如果光线批次的最后一个维度大于8,那么取最后三个元素作为视角方向,否则视角方向为None
bounds = torch.reshape(ray_batch[..., 6:8], [-1, 1, 2]) # 将光线批次的第7和第8个元素(即 near 和 far)重塑为形状为 [-1,1,2] 的张量
near, far = bounds[..., 0], bounds[..., 1] # [-1,1] # 从 bounds 张量中提取出 near 和 far,它们的形状都是 [-1,1]
t_vals = torch.linspace(0., 1., steps=N_samples) # 创建一个等差数列t_vals,范围从0到1,步长为N_samples
if not lindisp: # 根据lindisp的值,使用不同的公式计算z_vals
z_vals = near * (1. - t_vals) + far * (t_vals) # 如果lindisp为False,那么z_vals等于near乘以(1-t_vals)加上far乘以t_vals
else:
z_vals = 1. / (1. / near * (1. - t_vals) + 1. / far * (
t_vals)) # 如果lindisp为True,那么z_vals等于1除以(1/near乘以(1-t_vals)加上1/far乘以t_vals)
z_vals = z_vals.expand([N_rays, N_samples]) # 将z_vals扩展为[N_rays, N_samples]的形状
if perturb > 0.: # 判断 perturb 是否大于 0
# get intervals between samples # 获取样本之间的间隔
mids = .5 * (z_vals[..., 1:] + z_vals[..., :-1]) # 计算z_vals数组中相邻元素的平均值,并将结果存储在mids变量中
upper = torch.cat([mids, z_vals[..., -1:]], -1) # 将mids和z_vals的最后一个维度进行拼接,并将结果赋值给upper
lower = torch.cat([z_vals[..., :1], mids], -1) # 将z_vals的前n-1个元素与mids进行拼接,形成一个新的张量lower
# stratified samples in those intervals # 在那些间隔中进行分层采样
t_rand = torch.rand(z_vals.shape) # 生成一个与z_vals形状相同的随机张量,并将其赋值给t_rand
# Pytest, overwrite u with numpy's fixed random numbers # Pytest, 用numpy的固定随机数覆盖u
if pytest: # 如果pytest为真,则执行以下代码块
np.random.seed(0) # 设置随机数种子,确保每次运行结果一致
t_rand = np.random.rand(*list(z_vals.shape)) # 生成与z_vals形状相同的随机数数组t_rand
t_rand = torch.Tensor(t_rand) # 将t_rand转换为PyTorch张量
z_vals = lower + (upper - lower) * t_rand # 根据给定的范围和随机数计算z_vals的值
pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None] # [N_rays, N_samples, 3] # 计算射线上的采样点坐标
# raw = run_network(pts)
raw = network_query_fn(pts, viewdirs, network_fn) # 调用网络查询函数,传入参数pts, viewdirs和network_fn,获取原始输出结果raw
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd,
pytest=pytest) # 将原始输出结果raw转换为最终的输出结果rgb_map, disp_map, acc_map, weights, depth_map
if N_importance > 0: # 判断 N_importance 是否大于0
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map # 将rgb_map的值赋给rgb_map_0 将disp_map的值赋给disp_map_0 将acc_map的值赋给acc_map_0
z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1]) # 计算z_vals中相邻元素的平均值,并将结果存储在z_vals_mid中
z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], N_importance, det=(perturb == 0.),
pytest=pytest) # 使用给定的参数生成采样点
z_samples = z_samples.detach() # 将z_samples从计算图中分离,以便在反向传播过程中不计算梯度
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1) # 将z_vals和z_samples沿着最后一个维度进行拼接
pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :,
None] # [N_rays, N_samples + N_importance, 3]
# 计算射线与场景中的点的交点坐标
# rays_o: 射线的起点坐标,形状为 (N_rays, 3)
# rays_d: 射线的方向向量,形状为 (N_rays, 3)
# z_vals: 射线与场景中的点的交点的深度值,形状为 (N_rays, N_samples + N_importance)
# pts: 存储射线与场景中的点的交点坐标,形状为 (N_rays, N_samples + N_importance, 3)
run_fn = network_fn if network_fine is None else network_fine # 判断 network_fine 是否为 None,如果是,则将 network_fn 赋值给 run_fn,否则将 network_fine 赋值给 run_fn
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn) # 调用network_query_fn函数,传入参数pts, viewdirs和run_fn,并将结果赋值给raw变量
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd,
pytest=pytest) # 调用 raw2outputs 函数,传入相应的参数
ret = {'rgb_map': rgb_map, 'disp_map': disp_map,
'acc_map': acc_map} # 定义一个字典变量 ret,用于存储三个键值对 存储颜色映射信息 存储视差映射信息 存储累积映射信息
if retraw: # 判断变量retraw的值是否为True
ret['raw'] = raw # 将原始数据赋值给字典ret的'raw'键
if N_importance > 0: # 判断 N_importance 是否大于0
ret['rgb0'] = rgb_map_0 # 将rgb_map_0的值赋给ret字典中的'rgb0'键
ret['disp0'] = disp_map_0 # 将disp_map_0的值赋给ret字典中的'disp0'键
ret['acc0'] = acc_map_0 # 将变量acc_map_0的值赋给字典ret的键'acc0'
ret['z_std'] = torch.std(z_samples, dim=-1,
unbiased=False) # [N_rays] # 计算张量z_samples沿着最后一个维度的标准差,并将结果存储在ret字典的'z_std'键中 # N_rays表示射线的数量,unbiased=False表示使用无偏估计
for k in ret: # 遍历ret列表中的每个元素,将每个元素赋值给变量k
if (torch.isnan(ret[k]).any() or torch.isinf(
ret[k]).any()) and DEBUG: # 判断 ret[k] 中是否存在 NaN 或 Inf 值,如果存在并且 DEBUG 为 True,则执行后续代码
print(f"! [Numerical Error] {k} contains nan or inf.") # 打印格式化字符串,输出错误信息,提示变量k包含nan或inf
return ret # 返回变量ret的值